
Arjhun S
@arjunta_varudhuThis article will cover a wide range of topics related to NER. We’ll begin with a simple use case of NER using pre-existing models. From there, we’ll explore more sophisticated applications that require the creation of custom entities. To illustrate these concepts effectively, I’ll be leveraging one of my own open-source projects. The article aims to provide a comprehensive and detailed understanding of NER and its diverse applications.
What is NER?
NER stands for “Named Entity Recognition.” It’s like a superpower for computers to spot and understand important things in a chunk of text, just like how we humans can quickly pick out names, places, dates, or other specific stuff when reading.
Let’s imagine you’re a social media guru, and you want to analyse what people are saying about different tech companies on Twitter. You have thousands of tweets to go through, and it’s impossible to read them all manually. This is where NER comes to the rescue!
With NER, you can use a special tool or program that automatically scans through all those tweets and identifies specific entities like company names, products, and people mentioned in them. For instance, it can spot mentions of “Apple,” “iPhone,” “Elon Musk,” “Tesla,” “Microsoft,” and so on.
Now, armed with this information, you can quickly see which companies or products are getting the most attention on social media. You might discover that “Apple” is trending because of its new iPhone launch or that “Elon Musk” is making headlines due to some exciting Tesla news. Instead of sifting through a mountain of tweets, NER helps you get a snapshot of what’s hot and trending in the tech world. It’s like having a personal assistant who highlights all the crucial details so you can focus on making sense of the data and gaining valuable insights.
Pretty nifty, right?
Exploiting pre-trained models
There are several pre-trained models in libraries like nltk or spaCy which can be exploited to fit our problem.
These models are capable of understanding and analysing text, making them valuable tools for a wide range of use cases without requiring you to train a model from scratch.
This is a simple approach to using these models.
import nltk
# Download pre-trained NER model
nltk.download('maxent_ne_chunker')
nltk.download('words')
from nltk import pos_tag, ne_chunk
from nltk.tokenize import word_tokenize
text = "Barack Obama was born in Hawaii."
# Tokenize the text
tokens = word_tokenize(text)
# Perform part-of-speech tagging
pos_tags = pos_tag(tokens)
# Perform named entity recognition (NER)
ner_results = ne_chunk(pos_tags)
print(ner_results)Let’s go through the code line by line.
-
nltk.download('maxent_ne_chunker')andnltk.download('words'): These lines download the necessary data files for the maxent_ne_chunker and words modules, which are required for performing Named Entity Recognition (NER) using thene_chunkfunction. -
from nltk import pos_tag, ne_chunk: This line imports thepos_tagfunction for part-of-speech (POS) tagging and thene_chunkfunction for performing Named Entity Recognition (NER). -
from nltk.tokenize import word_tokenize: This line imports theword_tokenizefunction from thenltk.tokenizemodule, which is used to tokenize the input text into individual words or tokens. -
tokens = word_tokenize(text): This line tokenises the input text using theword_tokenizefunction, which breaks the text into individual words (tokens). The result is stored in thetokensvariable. -
pos_tags = pos_tag(tokens): This line performs part-of-speech (POS) tagging on the tokens using thepos_tagfunction. POS tagging assigns a grammatical tag to each word (noun, verb, adjective, etc.). The result is stored in thepos_tagsvariable. -
ner_results = ne_chunk(pos_tags): This line performs Named Entity Recognition (NER) using thene_chunkfunction. Thene_chunkfunction takes the POS-tagged tokens as input and identifies named entities (such as people, organisations, locations) in the text. The result is stored in thener_resultsvariable.
For the given input text "Barack Obama was born in Hawaii.," the output might look like:
(S (PERSON Barack/NNP Obama/NNP) was/VBD born/VBN in/IN (GPE Hawaii/NNP) ./.)Now, let’s go through the output line by line.
-
(S: This indicates that the text has been parsed as a sentence. -
(PERSON Barack/NNP Obama/NNP): This is a named entity recognised as a person. The NER model identified “Barack Obama” as a person, where “NNP” stands for “proper noun, singular.” In this representation, the label PERSON is assigned to this entity. -
was/VBD: This is a regular verb “was” with a “past tense” tag “VBD.” -
born/VBN: This is a verb “born” with a “past participle” tag “VBN.” -
in/IN: This is a preposition “in” with an “adposition” tag “IN.” -
(GPE Hawaii/NNP): This is another named entity recognised as a geopolitical entity. The NER model identified “Hawaii” as a place or location, where “NNP” stands for “proper noun, singular.” In this representation, the label GPE (Geo-Political Entity) is assigned to this entity.
Don’t worry if a most of it don’t make sense to you. It’s sufficient if you have a good grasp on the concept overall. It’s simpler than ever to create custom entities with far less complexity.
I will also include a spaCy version of the above implementation.
import spacy
# Download and load the pre-trained English model
nlp = spacy.load('en_core_web_sm')
text = "Barack Obama was born in Hawaii."
# Process the text with spaCy's NLP pipeline
doc = nlp(text)
# Extract named entities
for ent in doc.ents:
print(ent.text, ent.label_)Barack Obama PERSON
Hawaii GPEThis code is much simpler and self-explanatory.
en_core_web_sm is a pre-trained model in spaCy specifically designed for the english language. You can find more about it here.
Now that you have a basic understanding of NER. Let’s dive into a specific implementation.
The problem we’re trying to tackle here is the analysis of privacy policies. Nobody reads them right? Therefore, it would be useful if we could summarise it by extracting lines of potentially important information to any person about to accept to the terms mentioned in them.
In order to do that using NER, we have to create custom entities and group them together based on relative importance. We also need a potentially large dataset for this. You can download the dataset here.
In order to annotate the existing dataset, we need a set of categories (entities) and a corpus of terms/words that come under it. I used chatGPT to get the terms. However, I’m not including it here because of its size. But you could always get it from chatGPT with a few commands.
Some potentially important categories might include
business
law
regulations
usability
policy
privacy
education
technology
property
third-party
cookies
data
tracking
multi-disciplinaryOnce we have all this ready, we can start working.
import sqlite3
import pandas as pd
pd.set_option("display.max_colwidth", 60)
pd.set_option("display.max_rows", 100)
RELEASE_DB_NAME = "release_db.sqlite"
conn = sqlite3.connect(RELEASE_DB_NAME)
policy_texts_df = pd.read_sql_query("SELECT * FROM policy_texts", conn)
simply_the_text = policy_texts_df[["id", "policy_text"]]
# training on the first 1500 policies
simply_the_text = simply_the_text[:1500]Make sure you create labels.json and add the corpus with all the categories to it.
# use labels.json to label policies in simply_the_text dataframe
import json
with open('labels.json') as f:
labels = json.load(f)
# create a new column in simply_the_text dataframe called "label"
simply_the_text["label"] = ""
simply_the_text.head()
# for each policy in simply_the_text dataframe, find the corresponding label in labels.json
for i in range(len(simply_the_text)):
for title, labels_list in labels.items():
# if any word in labels_list appears in policy_text, then add the title in the labels. there can be multiple labels for each policy
if any(word in simply_the_text["policy_text"][i] for word in labels_list):
simply_the_text["label"][i] += ", " + title if simply_the_text["label"][i] != "" else title
with open('labels.json') as f:
labels = json.load(f)
# Create a new column in `simply_the_text` dataframe called "annotations"
simply_the_text["annotations"] = ""
# Iterate over each policy in `simply_the_text` dataframe
for i, row in simply_the_text.iterrows():
policy_text = row["policy_text"]
annotations = []
seen_tokens = set() # Track the tokens that have been seen
# Iterate over each label in labels.json
for label, label_keywords in labels.items():
# Check if any word in `label_keywords` appears in `policy_text`
for keyword in label_keywords:
start = policy_text.find(keyword)
while start != -1:
end = start + len(keyword)
if all(token not in seen_tokens for token in range(start, end)):
annotations.append((start, end, label))
seen_tokens.update(range(start, end))
start = policy_text.find(keyword, end)
# Add the annotations to the "annotations" column
simply_the_text.at[i, "annotations"] = {"entities": annotations}This adds all potential labels to a column called label to the simply_the_text dataframe. Moreover, it finds the starting point and ending points of the words that led to the labels being added and this is added to the annotations column.
An example of the dataset is as follows:

Data Preparation
train_data = simply_the_text.sample(frac=0.8, random_state=42)
test_data = simply_the_text.drop(train_data.index)In this part, the code prepares the training and testing datasets. It randomly samples 80% of the data from the DataFrame simply_the_text to create the training data and uses the remaining 20% to create the testing data.
Initializing the NLP Pipeline and Loading Labels
nlp = spacy.blank("en") # Use an appropriate spaCy model
# get all label titles from labels.json
import json
with open('labels.json') as f:
labels = json.load(f)
labels = list(labels.keys())
print(labels)Here, the code initialises a blank spaCy NLP pipeline for the English language using spacy.blank("en"). It creates an empty pipeline without any pre-trained components.
The code then loads label titles from a JSON file named labels.json. These labels are used to define the entities we want to recognise during NER. The labels will be added to the Named Entity Recognition (NER) component of the pipeline later.
Preparing Training Data for NER
train_data_ner = []
for _, row in train_data.iterrows():
doc = nlp.make_doc(row["policy_text"])
annotations = row["annotations"]
example = Example.from_dict(doc, annotations)
train_data_ner.append(example)In this part, the code prepares the training data in the required format for Named Entity Recognition (NER). It iterates through each row in the train_data DataFrame. For each row, it creates a spaCy Doc object from the policy text using nlp.make_doc. The annotations for each row are loaded, and an Example object is created using Example.from_dict, which contains the document and the corresponding annotations. The Example objects are collected in the train_data_ner list, which will be used for training the NER model.
Adding NER Component to the Pipeline and Training the Model
if "ner" not in nlp.pipe_names:
ner = nlp.create_pipe("ner")
nlp.add_pipe("ner", last=True)
else:
ner = nlp.get_pipe("ner")
for label in labels:
ner.add_label(label)
other_pipes = [pipe for pipe in nlp.pipe_names if pipe != "ner"]
with nlp.disable_pipes(*other_pipes):
optimizer = nlp.begin_training()
batch_sizes = compounding(4.0, 32.0, 1.001)
epochs = 8
all_losses = []
for epoch in range(epochs):
random.shuffle(train_data_ner)
losses = {}
batches = minibatch(train_data_ner, size=batch_sizes)
print(f"Epoch {epoch+1}/{epochs}")
for batch in batches:
nlp.update(batch, drop=0.3, losses=losses)
all_losses.append(losses)
print(f"Loss: {losses['ner']:.4f}")
# if loss increases, stop training
if epoch > 0 and losses["ner"] > all_losses[epoch-1]["ner"]:
break
nlp.to_disk("model")In this part, the code adds the NER component to the spaCy pipeline if it doesn’t already exist. It also adds the labels (entities) to the NER component.
The code then disables other pipeline components for training efficiency and starts training the NER model. It uses the nlp.begin_training() method to initialise the optimiser and define the learning rate.
The model is trained for a specified number of epochs (8 in this case). In each epoch, the training data is shuffled, and batches are generated using the minibatch function. The model is updated using the nlp.update method with a dropout rate of 0.3. The training losses for each epoch are recorded and printed.
The training stops early if the loss starts to increase, indicating that the model might be overfitting.
Evaluating the Model on the Testing Set
test_data_ner = []
for _, row in test_data.iterrows():
doc = nlp.make_doc(row["policy_text"])
annotations = row["annotations"]
example = Example.from_dict(doc, annotations)
test_data_ner.append(example)Here, the code prepares the testing data in the same format as the training data, creating a list of Example objects called test_data_ner.
Making Predictions Using the Trained Model
predictions = []
for example in test_data_ner:
doc = nlp(example.text)
entities = [(ent.text, ent.label_) for ent in doc.ents]
predictions.append(entities)In this part, the code uses the trained NER model to make predictions on the testing data. It iterates through each Example in test_data_ner, processes the text using the trained model, and extracts the recognised entities along with their labels. The predictions are stored in the predictions list.
Evaluating the Predictions
import matplotlib.pyplot as plt
import seaborn as sns
losses = [loss["ner"] for loss in all_losses]
sns.lineplot(x=range(len(losses)), y=losses)
plt.xlabel("epochs")
plt.ylabel("loss")
plt.show()
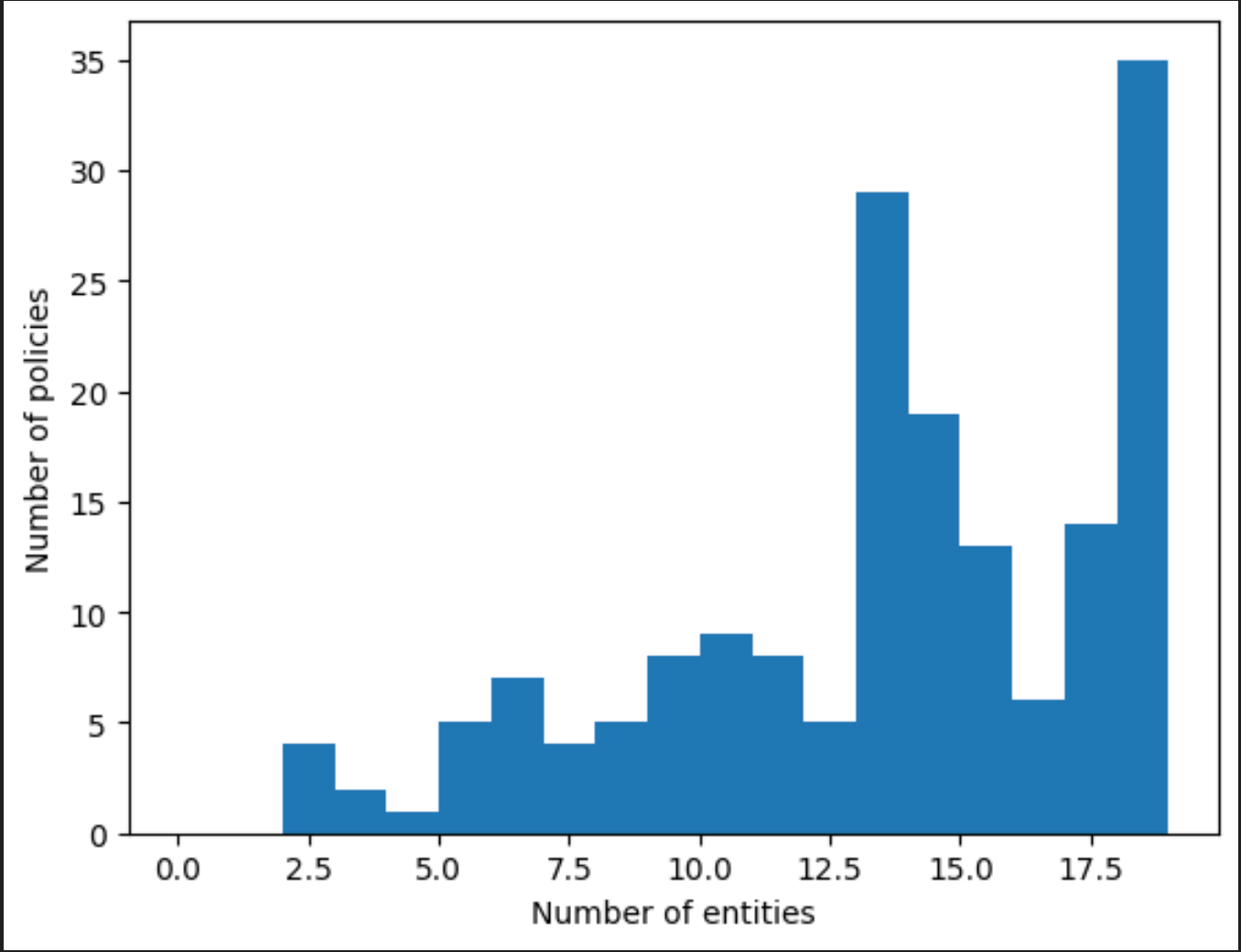
# entity distribution
# Get the number of entities in each policy
num_entities = [len(row["annotations"]["entities"]) for _, row in simply_the_text.iterrows()]
# Plot the distribution
plt.hist(num_entities, bins=range(0, 20, 1))
plt.xlabel("Number of entities")
plt.ylabel("Number of policies")
plt.show()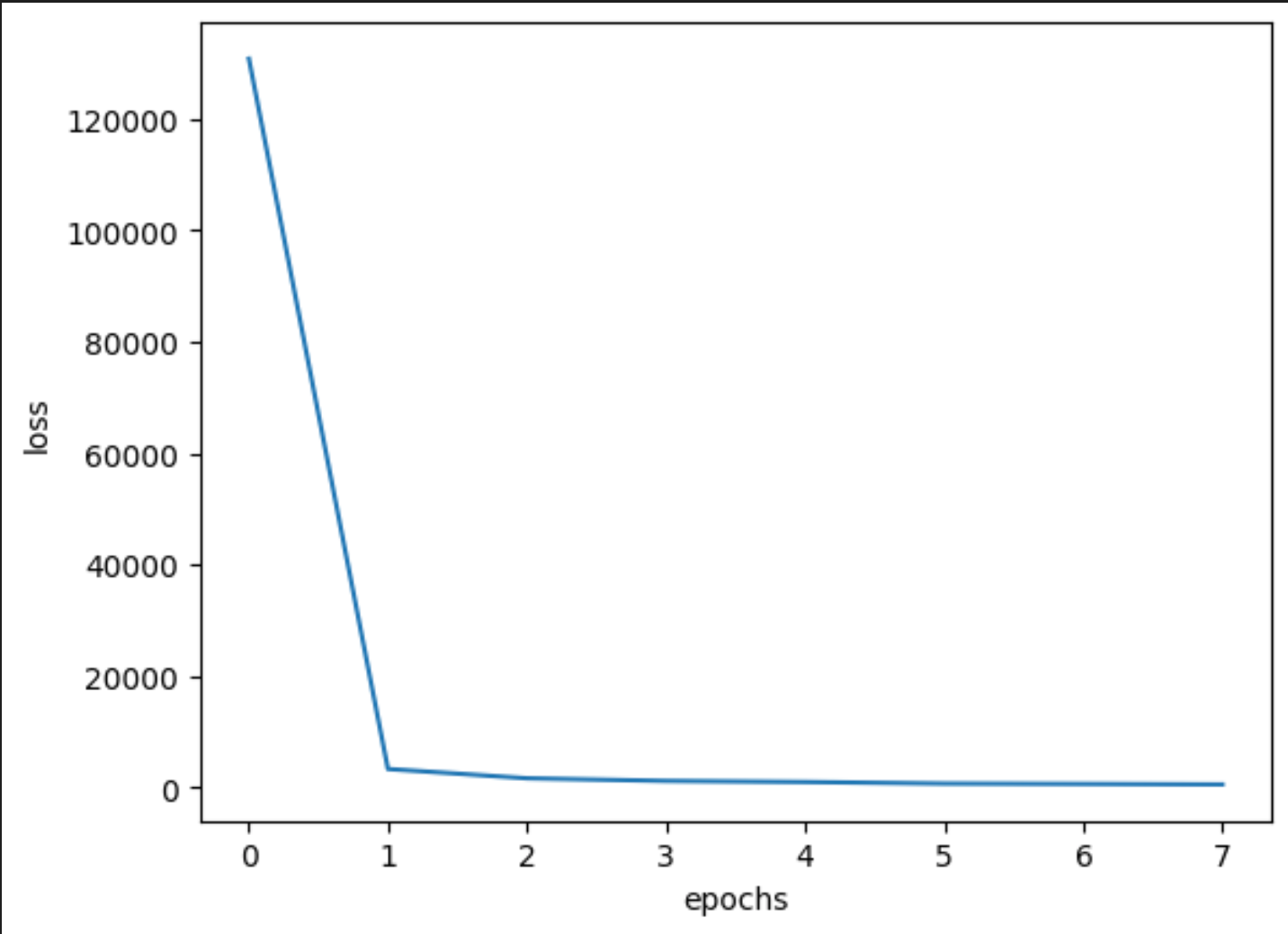
How do we use it?
# use the model
import spacy
nlp = spacy.load("model")
# Define a function to predict labels for a given text
def predict_labels(text):
doc = nlp(text)
entities = [(ent.text, ent.label_) for ent in doc.ents]
return entities
# Define a function to display the predicted labels
def display_predictions(text):
entities = predict_labels(text)
for entity in entities:
# find the last fullstop before the start of the entity
entity_start = text.find(entity[0])
entity_end = entity_start + len(entity[0])
start = text.rfind(".", 0, entity_start) + 1
# find the next fullstop after the end of the entity
end = text.find(".", entity_end) + 1
# print the sentence containing the entity
print(f"{text[start:end].strip()} : {entity[1]}")
text = policy_texts_df[["id", "policy_text"]]
display_predictions(text.iloc[1501, 1])Here is a first few lines of the output:
This MuleSoft Privacy Statement ("Privacy Statement") describes our
privacy practices. : privacy
Please read this Privacy Statement carefully to learn how we collect,
use, share and otherwise process information relating to individuals
("Personal Data"), and your rights and choices regarding our processing
of your Personal Data. : data
Therefore, your Personal Data may be processed outside the EEA, and in
countries which are not subject to an adequacy decision by the European
Commission and which may not provide for the same level of data protection
in the EEA. : law
Hence, we can clearly see how the defined entities work. Success!!
Now, we can create a simple interface to get this to work.

You can check out a hosted version of this code right here (the link is extremely slow because its hosted on a free tier on render).
The entire code is right here. Please do star the repository if you happen to drop by. Thank you for reading through, I hope you learnt something.
Cheers!